IMPORTANT NOTE: The NodeJS algorithm had a slight discrepancy in it. See this article for a correction to the performance comparison section of this article.
The Algorithm
Yesterday, I decided to try translate my algorithm for calculating N-Queens to JavaScript. I’ve implemented the same single-thread, brute force, recursive algorithm in many different languages with the biggest difference being the syntax of the language. Once I completed the JavaScript Implementation, I ran the program with the latest version of Node.js.
The Findings
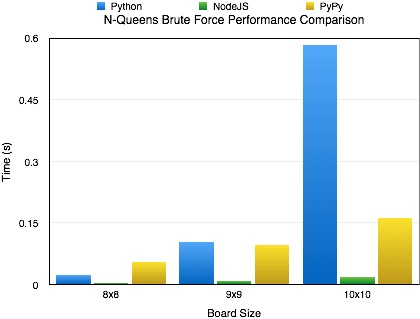
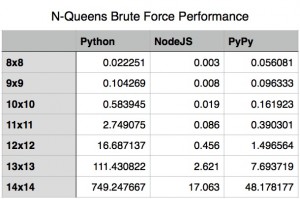
I knew Node was fast but it still surprised me. As you can see by the included charts, the performance difference between Node.js and out-of-the-box Python is pretty significant. Its not until the algorithms complexity and recursion depth hit certain limits that Node.js’s performance starts to falter.
Node.js and CPython – What’s The Difference?
You might ask what is behind this performance difference. The answer is actually pretty simple. It all boils down to how the code is being executed. Node.js uses the V8 JavaScript Engine (Wikipedia | Google) written by Google and a part of the Chrome Browser. V8 includes a just-in-time compiler that compiles the JavaScript to machine code before execution and then continuously optimizes the compiled code. Python is a bytecode interpreter; meaning that the default interpreter (CPython) doesn’t execute Python scripts directly. Instead, it first generates a intermediate file that will later be interpreted at runtime.
Ways To Get Better Performance
If you want to use Python, we can overcome the differences between Node.js and vanilla Python by using PyPy, an alternative implementation of Python that includes a just-in-time compiler. For the algorithm I wrote, you can see a pretty good performance boost over Node.js when using PyPy.
Special Notes
- I’ve placed my source on GitHub at the following url: https://github.com/chaddotson/puzzles
- This is just with one type of algorithm, the best solution might and probably does change depending on what type of application you are researching. For webserver performance, Node.js is slightly better than PyPy running Tornado.
- This algorithm is a simple brute force algorithm, there are many faster and better ones out there.
- At a board size of 15, Node.js could no longer run the algorithm due to its maximum recursion limit.
Edit – A Follow-Up
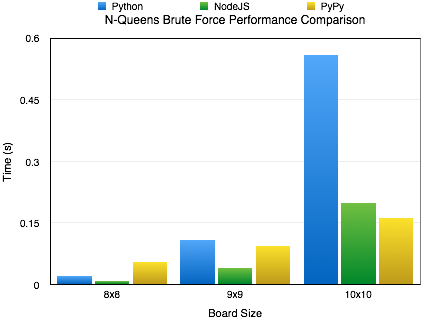
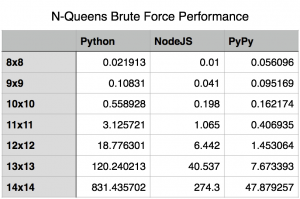
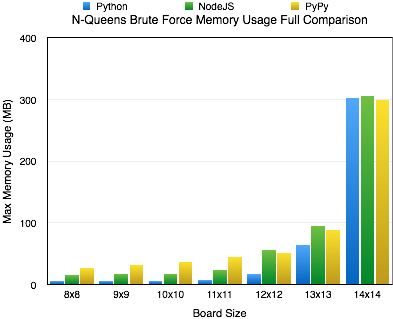
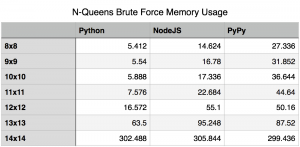
The original focus of this article was shear performance, but I’ve received a question regarding the memory footprint of the 3 methods. I think that is a very good and valid question. So, I reran the tests to capture the peak memory utilization by each. For this test I used “/usr/bin/time -l” to capture the maximum resident set size. While this isn’t exactly the peak amount of memory utilized by the algorithm, it is sufficiently close to report on.
New Findings
Upon rerunning the tests for capturing memory utilization, I found that for the most part memory utilization contrasts performance. A higher memory utilization isn’t really unexpected, if you think about it. Essentially, the jit is sacrificing memory for performance. In most cases, this isn’t really that bad. Using a jit is just a cheap way of boosting performance of code written in an interpreted language. The boost in performance, speed of which it was written and the maintainability of it outweigh memory utilization concerns in many cases.
The Oddity
As you can see, I’ve included a chart covering all the solutions for boards 8×8 to 14×14. During most increments in board size, the memory utilization seems to increase exponentially; however, when we hit the 14×14 board size we see all the cases level off at relatively the same memory utilization of around 300 MB. At this time, I really don’t have a good answer for this. I could certainly speculate, but I’d rather not until I know more.